If you write any code that deals with manual memory management, you are likely familiar with the concept of a “use after free” bug. These bugs can be the source of, at best, program crashes, and at worst serious vulnerabilities. A lesser discussed counterpart to use after free, is “use after return”. In some cases, the latter can be even more troublesome, due to the operations that are performed when one procedure calls another. In this post, we’ll take a look at what happens under the hood when a RISC-V program includes a use after return bug, as well as how “higher-level” programming languages can guard against this behavior, at varying levels of cost to the programmer.
If you aren’t familiar with the RISC-V Bytes series, it may be worth giving our first post, Cross-Platform Debugging with QEMU and GDB, a quick read to get the necessary tools installed to follow along.
A Small C Program Link to heading
Let’s start off by taking a look at a small C program:
main.c
#include <stdio.h>
int *g;
void first()
{
int a = 1;
g = &a;
}
void second()
{
int b = 2;
}
int main(int argc, char **argv)
{
first();
second();
printf("%d\n", *g);
return 0;
}
This program is meant to run in userspace (U mode in RISC-V
vernacular),
meaning that it depends on some initialization that runs before main() (via
crt0), as well as system libraries and
functionality offered by the operating system, such as the ability to print to
stdout. We have one global
variable, g, which is a pointer to a 32-bit integer (the default in C for our
64-bit machine), and we call two procedures, first() then second(), before
printing the contents of the address pointed to by g, then exiting.
You may be able to guess what the output of this program will be, but let’s compile it, then run it and see. We’ll use an unoptimized build to get a simplified, albeit somewhat unrealistic, picture of what is going on.
$ riscv64-unknown-linux-gnu-gcc -static main.c
GCC Version: 11.1.0
Note:
gcccompiles dynamically linked executables by default, but we opt to pass the-staticflag here to compile a statically linked executable. This makes it a bit easier to run on a different host architecture viabinfmt_miscbecause we don’t have to invoke our RISC-V dynamic linker at runtime.
Let’s run our program and check the output:
$ ./a.out
2
Interesting! Despite only ever assigning the address of a, which contains the
32-bit integer 1, to g, the contents of that address contain the value 2
when we print. We do assign 2 to the variable b in second(), but how does
that end up as the value at the address in g? The crux of the issue is that we
are using variables together that have different lifetimes. While g is
defined at the global scope, and thus exists for the entire lifetime of the
program, a is defined only in the scope of first(), meaning that the program
has no concept of a once the function returns.
But we still haven’t explained why the value stored in b, which has a lifetime
scoped to second() has ended up at the address stored in g. Let’s take a
look at what is happening in the generated machine code.
$ riscv64-unknown-linux-gnu-objdump -D a.out | less
Note: there are many ways to explore the disassembled content of an executable. A pattern that I have found useful is piping
objdump -Dintoless, then searching for the symbol I’m looking for, in this case using/main. You can step forward through the matches usingn, and step backward usingShift+N.
00000000000105d2 <first>:
105d2: 1101 addi sp,sp,-32
105d4: ec22 sd s0,24(sp)
105d6: 1000 addi s0,sp,32
105d8: 4785 li a5,1
105da: fef42623 sw a5,-20(s0)
105de: fec40713 addi a4,s0,-20
105e2: 9ae1b823 sd a4,-1616(gp) # 70a78 <g>
105e6: 0001 nop
105e8: 6462 ld s0,24(sp)
105ea: 6105 addi sp,sp,32
105ec: 8082 ret
00000000000105ee <second>:
105ee: 1101 addi sp,sp,-32
105f0: ec22 sd s0,24(sp)
105f2: 1000 addi s0,sp,32
105f4: 4789 li a5,2
105f6: fef42623 sw a5,-20(s0)
105fa: 0001 nop
105fc: 6462 ld s0,24(sp)
105fe: 6105 addi sp,sp,32
10600: 8082 ret
0000000000010602 <main>:
10602: 1101 addi sp,sp,-32
10604: ec06 sd ra,24(sp)
10606: e822 sd s0,16(sp)
10608: 1000 addi s0,sp,32
1060a: 87aa mv a5,a0
1060c: feb43023 sd a1,-32(s0)
10610: fef42623 sw a5,-20(s0)
10614: fbfff0ef jal ra,105d2 <first>
10618: fd7ff0ef jal ra,105ee <second>
1061c: 9b01b783 ld a5,-1616(gp) # 70a78 <g>
10620: 439c lw a5,0(a5)
10622: 85be mv a1,a5
10624: 0004c7b7 lui a5,0x4c
10628: 26078513 addi a0,a5,608 # 4c260 <free_mem+0xc4>
1062c: 5cc040ef jal ra,14bf8 <_IO_printf>
10630: 4781 li a5,0
10632: 853e mv a0,a5
10634: 60e2 ld ra,24(sp)
10636: 6442 ld s0,16(sp)
10638: 6105 addi sp,sp,32
1063a: 8082 ret
Check yourself: why is the difference in address from one instruction to another sometimes
2(2bytes ==16bits) (example:10604 - 10602 = 2) and sometimes4(4bytes ==32bits) (example:10614 - 10610 = 4)? Our 64-bit RISC-V GCC install is using-march=rv64imafdc. The final extension,c, corresponds to “Compressed”, which allows the compiler to compress some instructions to reduce code size. Every instruction in RISC-V is32bits, but when the compressed extension is enabled, some instructions can be represented in just16bites.
Starting with main, we see our typical function prologue, where the stack is
being grown by 32 bytes (10602), the return address (ra) is being stored
at the top of the stack frame (10604), and the previous frame pointer (s0)
is being stored just below it (10606) before eventually updating the frame
pointer to point to the top of main’s 32 byte stack frame (10608). The
next three instructions are not consequential for our investigation today, and
are only present here due to the fact that we are compiling with no
optimization, but for completeness, we are taking the arguments passed to
main() and storing them in its stack frame. a0, which gets moved to a5
(1060a), contains argc, a 32-bit integer specifying the number of arguments
passed. Because we are targeting a 64 bit machine, word size is 32 bits,
so we can use sw (“store word”) to store argc in main’s stack frame close
to the bottom (10610). Similarly, a1, which contains argc, a pointer (or
more specifically, a pointer to a pointer) to the arguments passed to the
program, gets put at the very bottom of the stack frame (1060c).
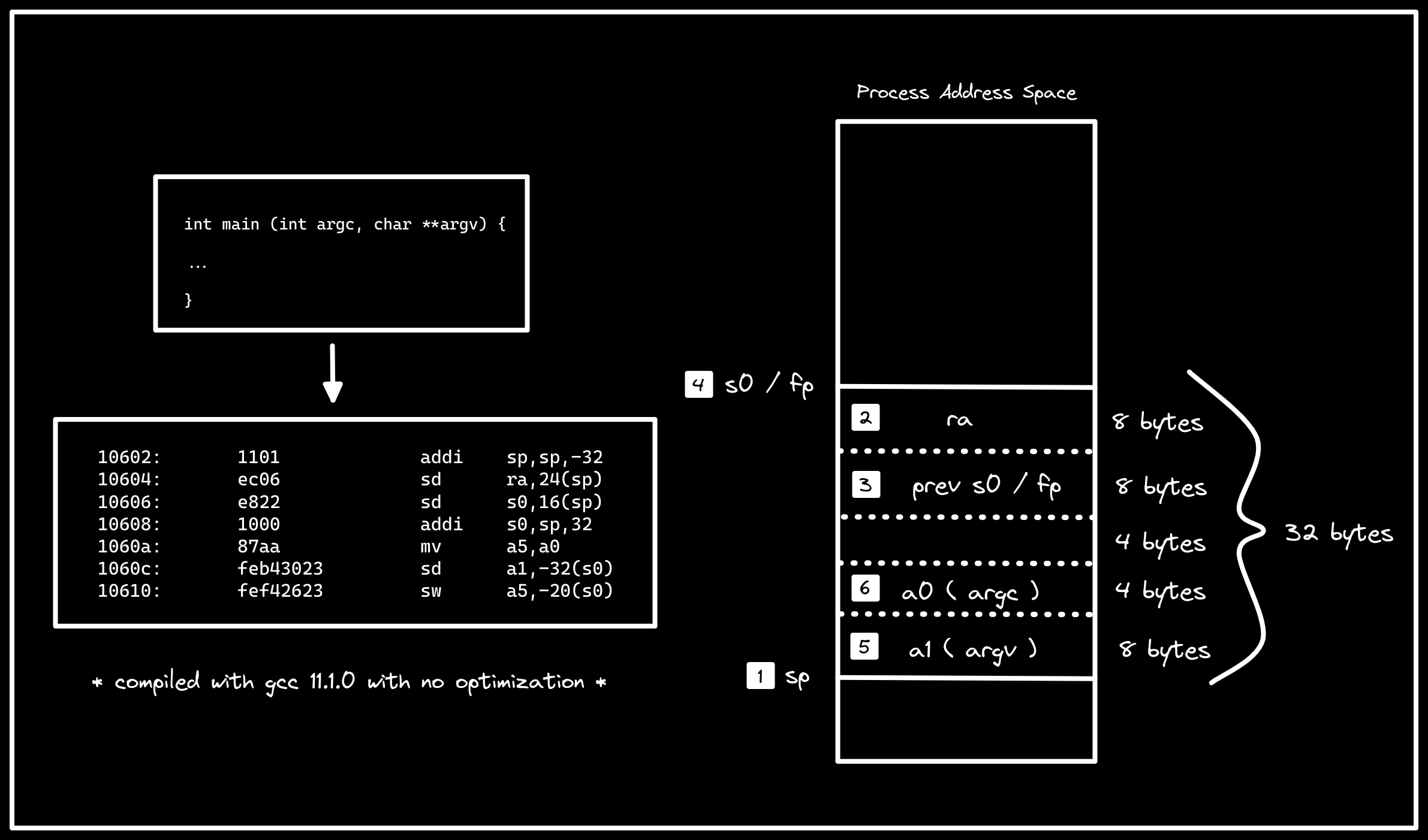
Description: visualization of function prologue for
main(). Note that themv a5,a0instruction is omitted from numbered operations on the stack.
Now we are ready to jump to first(). We see a similar function prologue,
before storing 1 into the a5 register (105d8), subsequently storing the
value on the stack (105da), then finally storing the stack address into a4
(105de). Lastly, we update g with the stack address from a4, such that it
now points to a memory location where the value 1 is stored. Though we haven’t
reached where g eventually points to 2, we have already made the mistake
that can lead to a “use after return” vulnerability. If we step through our
program with GDB, we can identify the exact
address in g after first().
In one terminal start QEMU, but wait for GDB to attach on port 1234:
$ qemu-riscv64 -g 1234 a.out
And in another start GDB by attaching to QEMU and setting a break point at
first():
$ riscv64-unknown-linux-gnu-gdb a.out -ex "target remote :1234" -ex "break first"
(gdb) c
Continuing.
Breakpoint 1, 0x00000000000105d8 in first ()
(gdb) x/8i $pc
=> 0x105d8 <first+6>: li a5,1
0x105da <first+8>: sw a5,-20(s0)
0x105de <first+12>: addi a4,s0,-20
0x105e2 <first+16>: sd a4,-1616(gp)
0x105e6 <first+20>: nop
0x105e8 <first+22>: ld s0,24(sp)
0x105ea <first+24>: addi sp,sp,32
0x105ec <first+26>: ret
After continuing to first() (GDB will frequently skip the function prologue by
default), we see the same function body that we dumped above. We are interested
in the address that is stored in a4 by the addi instruction at address
0x105de (<first+12>). It is a location in first’s stack frame calculated
using an offset of -20 from the frame pointer s0.
(gdb) i r s0 a4 sp
s0 0x40007ffd90 0x40007ffd90
a4 0x40007ffd7c 274886294908
sp 0x40007ffd70 0x40007ffd70
Printing s0, a4, and sp shows us that the address stored in a4 is in
fact 20 bytes below the frame pointer (0x40007ffd90 - 0x40007ffd7c = 0x14 = 20) and 12 bytes above the stack pointer (0x40007ffd7c - 0x40007ffd70 = 0xc = 12). This is fine as long as we are within first’s body, but as soon as we
return our stack frame changes. We can see this happening in the function
epilogue:
(gdb) x/4i $pc
=> 0x105e6 <first+20>: nop
0x105e8 <first+22>: ld s0,24(sp)
0x105ea <first+24>: addi sp,sp,32
0x105ec <first+26>: ret
We restore the previous frame pointer in 0x105e8 (<first+22>), then restore
the stack pointer in 0x105ea (<first+24>). By the time we return to main
the address in a4 is outside of the frame (i.e. below the stack pointer):
(gdb) si
0x00000000000105e8 in first ()
(gdb) si
0x00000000000105ea in first ()
(gdb) si
0x00000000000105ec in first ()
(gdb) si
0x0000000000010618 in main ()
(gdb) i r s0 a4 sp
s0 0x40007ffdb0 0x40007ffdb0
a4 0x40007ffd7c 274886294908
sp 0x40007ffd90 0x40007ffd90
More importantly, g is now a dangling
pointer.
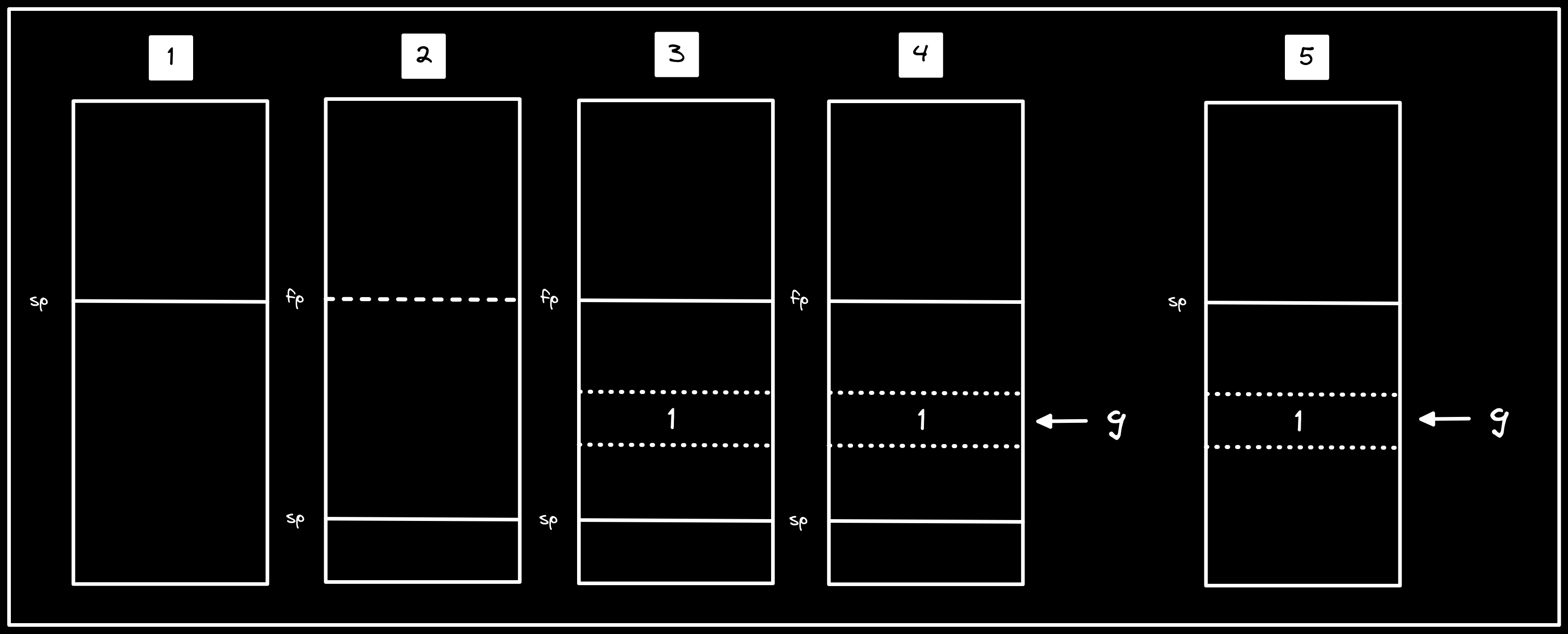
Description: visualization of steps in
first(), which includes: growing the stack, storing1on the stack, updatinggto point to the location of1on the stack, then shrinking the stack.
Our next instruction is a jump (jal - “jump and link”) to second(), where we
are again setting up a 32 byte stack frame, then storing a value in it:
(gdb) si
0x00000000000105ee in second ()
(gdb) x/8i $pc
=> 0x105ee <second>: addi sp,sp,-32
0x105f0 <second+2>: sd s0,24(sp)
0x105f2 <second+4>: addi s0,sp,32
0x105f4 <second+6>: li a5,2
0x105f6 <second+8>: sw a5,-20(s0)
0x105fa <second+12>: nop
0x105fc <second+14>: ld s0,24(sp)
0x105fe <second+16>: addi sp,sp,32
You’ll notice that the instruction at address 0x105f6 (<second+8>) is the
same instruction we saw in first() at 0x105da (<first+8>). Let’s step to
that instruction, and look at the contents of g before and after.
(gdb) si
0x00000000000105f0 in second ()
(gdb) si
0x00000000000105f2 in second ()
(gdb) si
0x00000000000105f4 in second ()
(gdb) si
0x00000000000105f6 in second ()
(gdb) p /s (int*)g
$4 = (int *) 0x40007ffd7c
(gdb) x/d 0x40007ffd7c
0x40007ffd7c: 1
(gdb) si
0x00000000000105fa in second ()
(gdb) p /s (int*)g
$5 = (int *) 0x40007ffd7c
(gdb) x/d 0x40007ffd7c
0x40007ffd7c: 2
While g continues to point at the same address (0x40007ffd7c), that address
is now part of second’s stack frame, meaning that it is free to allocate local
variables in the range. Without explicitly assigning to g, we have implicitly
changed its value. This is a fairly trivial example, but in more extreme cases
this type of implicit assignment could allow a user to manipulate the output, or
worse, the control flow, of the program just by supplying certain inputs.
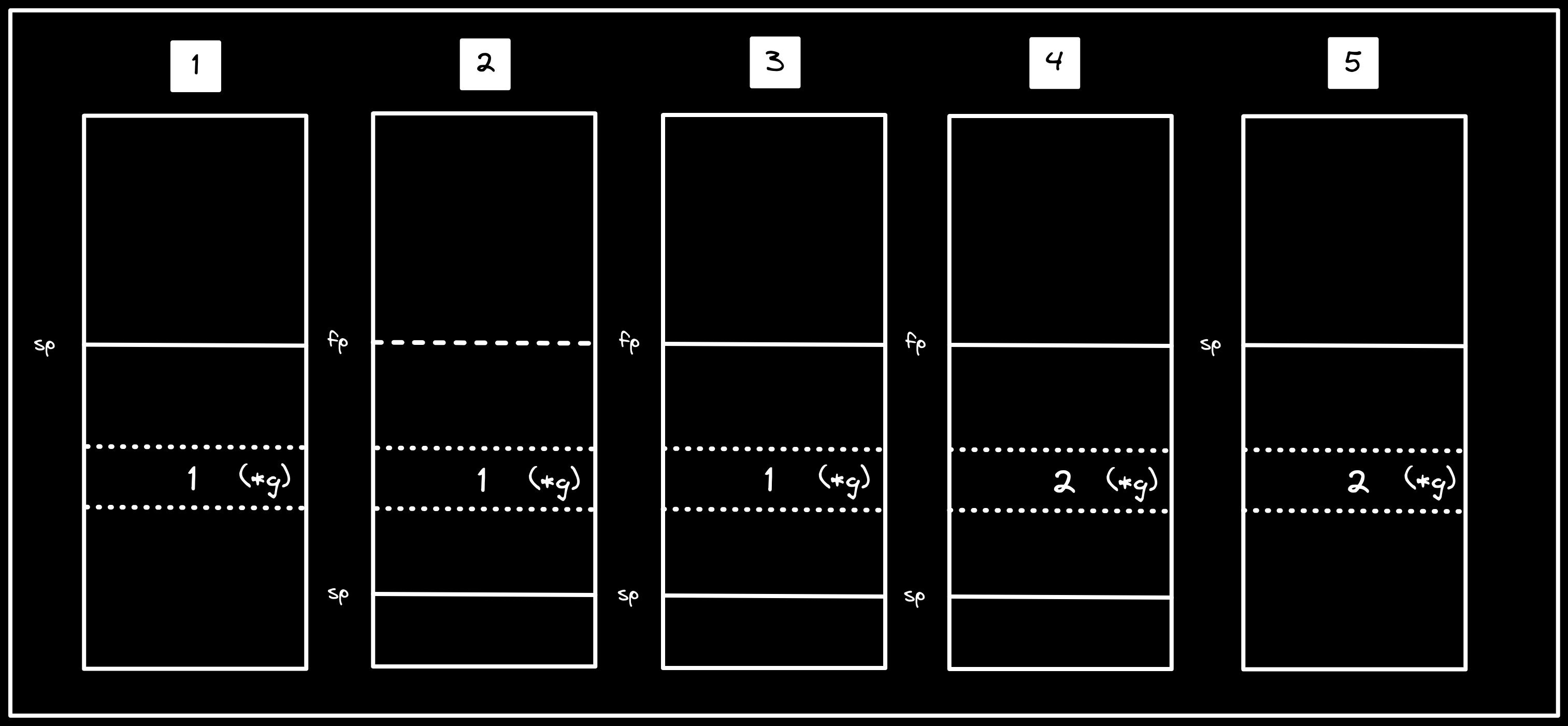
Description: visualization of steps in
second(), which includes: growing the stack to include the address ing(which currently contains1), overwriting the value to2, then shrinking the stack again.
How Does Go Handle This? Link to heading
One of the reasons why folks reach for “memory safe” languages these days is to avoid accidentally introducing vulnerabilities with mistakes like the one described above. One way “memory safe” languages handle this is via a built-in runtime and garbage collector. Go is a popular language that takes this approach. Let’s look at a sibling program to the one we have already been exploring.
main.go
package main
import "fmt"
var g *int
func first() {
a := 1
g = &a
}
func second() {
b := 2
// Assign to blank identifier to satisfy compiler.
_ = b
}
func main() {
first()
second()
fmt.Println(*g)
}
This is almost identical to the C program we saw before. However, when we compile we’ll see the generated machine code is quite different. As before, we’ll disable optimization using the following Go compiler flags:
-N: disable optimizations-l: disable inlining-m: print optimization decisions
$ GOOS=linux GOARCH=riscv64 go build -gcflags '-N -l -m' main.go
# command-line-arguments
./main.go:8:2: moved to heap: a
./main.go:21:13: ... argument does not escape
./main.go:21:14: *g escapes to heap
Go Version: 1.18.4
If we run the program, we’ll see we that, unlike our C program, we get the
expected value of 1.
$ ./main
1
Without even examining the machine code, the -m flag is causing the compiler
to emit information about how it is handling our assignment of the address of a
local variable (a) with a temporary lifetime to a global variable (g) that
outlives it. This is explained in the Go
FAQ:
How do I know whether a variable is allocated on the heap or the stack?
From a correctness standpoint, you don’t need to know. Each variable in Go exists as long as there are references to it. The storage location chosen by the implementation is irrelevant to the semantics of the language.
The storage location does have an effect on writing efficient programs. When possible, the Go compilers will allocate variables that are local to a function in that function’s stack frame. However, if the compiler cannot prove that the variable is not referenced after the function returns, then the compiler must allocate the variable on the garbage-collected heap to avoid dangling pointer errors. Also, if a local variable is very large, it might make more sense to store it on the heap rather than the stack.
In the current compilers, if a variable has its address taken, that variable is a candidate for allocation on the heap. However, a basic escape analysis recognizes some cases when such variables will not live past the return from the function and can reside on the stack.
In our program, a fits the description of a variable that the compiler cannot
prove is not referenced after the function returns. The compiler will allocate
a on the heap, making us no longer susceptible to the use after return
vulnerability.
Because Go does have a fairly large runtime, stepping through a program’s execution is more complex and requires knowledge of the language’s internals to fully understand what is going on. For example, the Go runtime maintains a separate stack per goroutine, which can be dynamically expanded as needed, meaning that understanding a given function’s stack frame is not as simple as examining the the stack and frame pointer after the prologue. Futhermore, Go has an internal ABI that does not guarantee backwards compatibility and differs from one architecture to another.
The Go team recommends using Delve for debugging as it is specifically built to understand Go programs. However, Delve does not currently support RISC-V, so we’ll stick with GDB today, which can still be useful if you know where to look (and has the advantage of using consistent tooling across languages). Before we jump into GDB, let’s dump our machine code:
$ riscv64-unknown-linux-gnu-objdump -D main | less
0000000000090020 <main.first>:
90020: 010db503 ld a0,16(s11)
90024: 00256663 bltu a0,sp,90030 <main.first+0x10>
90028: ac8da2ef jal t0,6a2f0 <runtime.morestack_noctxt>
9002c: ff5ff06f j 90020 <main.first>
90030: fc113c23 sd ra,-40(sp)
90034: fd810113 addi sp,sp,-40
90038: 00016297 auipc t0,0x16
9003c: 68828293 addi t0,t0,1672 # a66c0 <type.*+0x66c0>
90040: 00513423 sd t0,8(sp)
90044: ff58a0ef jal ra,1b038 <runtime.newobject>
90048: 01013283 ld t0,16(sp)
9004c: 02513023 sd t0,32(sp)
90050: 00100313 li t1,1
90054: 0062b023 sd t1,0(t0)
90058: 000e5297 auipc t0,0xe5
9005c: 2b82e283 lwu t0,696(t0) # 175310 <runtime.writeBarrier>
90060: 02013303 ld t1,32(sp)
90064: 00028463 beqz t0,9006c <main.first+0x4c>
90068: 0100006f j 90078 <main.first+0x58>
9006c: 000b8f97 auipc t6,0xb8
90070: 086fba23 sd t1,148(t6) # 148100 <main.g>
90074: 0140006f j 90088 <main.first+0x68>
90078: 000b8297 auipc t0,0xb8
9007c: 08828293 addi t0,t0,136 # 148100 <main.g>
90080: ff1db0ef jal ra,6c070 <runtime.gcWriteBarrier>
90084: 0040006f j 90088 <main.first+0x68>
90088: 00013083 ld ra,0(sp)
9008c: 02810113 addi sp,sp,40
90090: 00008067 ret
90094: 0000 unimp
...
0000000000090098 <main.second>:
90098: 010db503 ld a0,16(s11)
9009c: 00256663 bltu a0,sp,900a8 <main.second+0x10>
900a0: a50da2ef jal t0,6a2f0 <runtime.morestack_noctxt>
900a4: ff5ff06f j 90098 <main.second>
900a8: fe113823 sd ra,-16(sp)
900ac: ff010113 addi sp,sp,-16
900b0: 00200293 li t0,2
900b4: 00513423 sd t0,8(sp)
900b8: 00013083 ld ra,0(sp)
900bc: 01010113 addi sp,sp,16
900c0: 00008067 ret
900c4: 0000 unimp
...
Note:
<main.main>is omitted above for brevity as we are primarily interested in the difference between what is happening in<main.first>and<main.second>.
There is a lot more going on in first() and second() than in our original C
program, but we still see some of the same operations, such as growing (e.g.
90034, 900ac) and shrinking (e.g. 9008c, 900bc) the stack frame by
changing the address in sp. A notable difference exists in the function
prologue, which includes a check (e.g. 90024, 9009c) comparing the stack
pointer (sp) to what is the current goroutine’s “stack guard” (i.e.
16(s11)). This check is what determines whether we need to dynamically grow
the goroutine stack via a call to runtime.morestack.
However, what we primarily care about for the purposes of this post is the
following instructions in first():
90038: 00016297 auipc t0,0x16
9003c: 68828293 addi t0,t0,1672 # a66c0 <type.*+0x66c0>
90040: 00513423 sd t0,8(sp)
90044: ff58a0ef jal ra,1b038 <runtime.newobject>
90048: 01013283 ld t0,16(sp)
9004c: 02513023 sd t0,32(sp)
90050: 00100313 li t1,1
90054: 0062b023 sd t1,0(t0)
...
In contrast to just loading the value (1) into a register then storing to the
stack, we are:
- Storing a reference to the type information of the object (of type
*_type). In this case, the066c0address just points to a value of0x8in memory, as the 64-bit integer we are storing has size of8bytes. (instructions:90038-9003c). - Passing that type information (on the stack, more on this in a moment) to
runtime.newobject(ref). This function ultimately callsruntime.mallocgc(ref), which allocates the necessary memory on the heap, and returns an address to it. (instructions:90040-90044) - Loading the value of
1intot1, then storing it in memory to the address returned fromruntime.newobject(which is now int0). (instructions:90048-90054)
One area of note for us is that Go currently uses a “stack-based calling convention”, meaning that all arguments and return values are passed from one procedure to another on the stack. There is work being done to instead utilize registers, which modern CPUs can access much faster in many scenarios, as described in this proposal. You can read more about passing on the stack in RISC-V in an earlier post in the RISC-V Bytes series.
Note: it appears that RISC-V support for the register-based calling convention will be available in Go 1.19! A future post will compare this updated calling convention with the generated machine code we are exploring today.
Now that we have stored 1 on the heap, we need to update the address that g
contains. This occurs in the subsequent instructions:
90058: 000e5297 auipc t0,0xe5
9005c: 2b82e283 lwu t0,696(t0) # 175310 <runtime.writeBarrier>
90060: 02013303 ld t1,32(sp)
90064: 00028463 beqz t0,9006c <main.first+0x4c>
90068: 0100006f j 90078 <main.first+0x58>
9006c: 000b8f97 auipc t6,0xb8
90070: 086fba23 sd t1,148(t6) # 148100 <main.g>
90074: 0140006f j 90088 <main.first+0x68>
90078: 000b8297 auipc t0,0xb8
9007c: 08828293 addi t0,t0,136 # 148100 <main.g>
90080: ff1db0ef jal ra,6c070 <runtime.gcWriteBarrier>
90084: 0040006f j 90088 <main.first+0x68>
90088: 00013083 ld ra,0(sp)
9008c: 02810113 addi sp,sp,40
90090: 00008067 ret
...
This may look confusing at first as it appears there are two different sequences
that update g (i.e. <main.g>). However, any execution of first() will
result in only one of these operations being performed, with the deciding factor
being the state of the garbage collector. If the garbage collector is in either
the _GCmark
(ref)
or _GCmarktermination
(ref)
phases the runtime.writeBarrier enabled flag
(ref)
will be
set.
For our purposes, this just means that we have to inform the garbage collector
when we are performing certain memory write operations. In this case, we are
preforming a global
write,
and we must write through runtime.gcWriteBarrier
(ref)
if runtime.writeBarrier.enabled is set.
Note: you can read more about write barriers and the garbage collector in the heavily documented Go runtime source code.
In full, we are performing the following steps:
- Loading
runtime.writeBarrier.enabledintot0. (instructions:90058-9005c) - Loading the address in
a, which was provided byruntime.newobjectand stored on the stack, intot1. (instruction:90060) - Checking whether
runtime.writeBarrier.enabledis set. If it is equal to0(i.e. not set) then we break (beqz) to the address after the jump (j) in the subsequent instruction (90068), and write the address int1directly togwithout informing the garbage collector. If the write barrier is enabled, we instead proceed to the jump, skipping our direct write, and load the address ofgintot0and callruntime.gcWriteBarrier. (instructions:90064-90084). - Finally, restoring the return address (
ra) and stack pointer (sp) and returning. (instructions:90088-90090)
Note: the aforementioned “stack-based calling convention” is not applied with
runtime.gcWriteBarrier, which receives the destination write address int0, and the source value int1. This is called out in the implementation.
Because the address in g lives on the heap, we won’t encounter the same issue
we saw in our C program when we subsequently call second() and write 2 on
the stack for b. Let’s fire up GDB to see this in action.
Start QEMU:
$ qemu-riscv64 -g 1234 main
Start GDB:
$ riscv64-unknown-linux-gnu-gdb main -ex "target remote :1234" -ex "break main.first" -ex "break main.second"
Breakpoint 1 at 0x90044: file /home/dan/code/github.com/hasheddan/blog-code/main.go, line 8.
Breakpoint 2 at 0x900b0: file /home/dan/code/github.com/hasheddan/blog-code/main.go, line 13.
(gdb) c
Continuing.
[New Thread 1.152910]
[New Thread 1.152911]
[New Thread 1.152912]
[New Thread 1.152913]
[New Thread 1.152914]
Thread 1 hit Breakpoint 1, 0x0000000000090044 in main.first () at /home/dan/code/github.com/hasheddan/blog-code/main.go:8
8 a := 1
(gdb) x/8i $pc
=> 0x90044 <main.first+36>: jal ra,0x1b038 <runtime.newobject>
0x90048 <main.first+40>: ld t0,16(sp)
0x9004c <main.first+44>: sd t0,32(sp)
0x90050 <main.first+48>: li t1,1
0x90054 <main.first+52>: sd t1,0(t0)
0x90058 <main.first+56>: auipc t0,0xe5
0x9005c <main.first+60>: lwu t0,696(t0)
0x90060 <main.first+64>: ld t1,32(sp)
(gdb) n
warning: multi-threaded target stopped without sending a thread-id, using first non-exited thread
9 g = &a
(gdb) x/8i $pc
=> 0x90058 <main.first+56>: auipc t0,0xe5
0x9005c <main.first+60>: lwu t0,696(t0)
0x90060 <main.first+64>: ld t1,32(sp)
0x90064 <main.first+68>: beqz t0,0x9006c <main.first+76>
0x90068 <main.first+72>: j 0x90078 <main.first+88>
0x9006c <main.first+76>: auipc t6,0xb8
0x90070 <main.first+80>: sd t1,148(t6)
0x90074 <main.first+84>: j 0x90088 <main.first+104>
(gdb) i r t0 t1
t0 0xc0000c4000 824634523648
t1 0x1 1
(gdb) x /d $t0
0xc0000c4000: 1
So far we have seen that runtime.newobject did in fact give us an address on
the heap, and that we have written 1 to that address. Next, let’s check
whether runtime.writeBarrier.enabled is set.
(gdb) si
0x000000000009005c 9 g = &a
(gdb) si
0x0000000000090060 9 g = &a
(gdb) i r t0
t0 0x0 0
Because the write barrier is not enabled (i.e. t0 = 0), we should break and
write directly to g.
(gdb) x/8i $pc
=> 0x90060 <main.first+64>: ld t1,32(sp)
0x90064 <main.first+68>: beqz t0,0x9006c <main.first+76>
0x90068 <main.first+72>: j 0x90078 <main.first+88>
0x9006c <main.first+76>: auipc t6,0xb8
0x90070 <main.first+80>: sd t1,148(t6)
0x90074 <main.first+84>: j 0x90088 <main.first+104>
0x90078 <main.first+88>: auipc t0,0xb8
0x9007c <main.first+92>: addi t0,t0,136
(gdb) si
0x0000000000090064 9 g = &a
(gdb) si
9 g = &a
(gdb) x/8i $pc
=> 0x9006c <main.first+76>: auipc t6,0xb8
0x90070 <main.first+80>: sd t1,148(t6)
0x90074 <main.first+84>: j 0x90088 <main.first+104>
0x90078 <main.first+88>: auipc t0,0xb8
0x9007c <main.first+92>: addi t0,t0,136
0x90080 <main.first+96>: jal ra,0x6c070 <runtime.gcWriteBarrier>
0x90084 <main.first+100>: j 0x90088 <main.first+104>
0x90088 <main.first+104>: ld ra,0(sp)
And we do! Finally, let’s continue to second() and take a look at the stack
address that 2 is written to.
(gdb) c
Continuing.
Thread 1 hit Breakpoint 2, 0x00000000000900b0 in main.second () at /home/dan/code/github.com/hasheddan/blog-code/main.go:13
13 b := 2
(gdb) x/8i $pc
=> 0x900b0 <main.second+24>: li t0,2
0x900b4 <main.second+28>: sd t0,8(sp)
0x900b8 <main.second+32>: ld ra,0(sp)
0x900bc <main.second+36>: addi sp,sp,16
0x900c0 <main.second+40>: ret
0x900c4: unimp
0x900c6: unimp
0x900c8 <main.main>: ld a0,16(s11)
(gdb) si
13 b := 2
(gdb) si
16 }
(gdb) x /d $sp+8
0xc0000aaf00: 2
Here we are able to safely write to the stack because the compiler is able to
determine that we don’t have any references that outlive second().
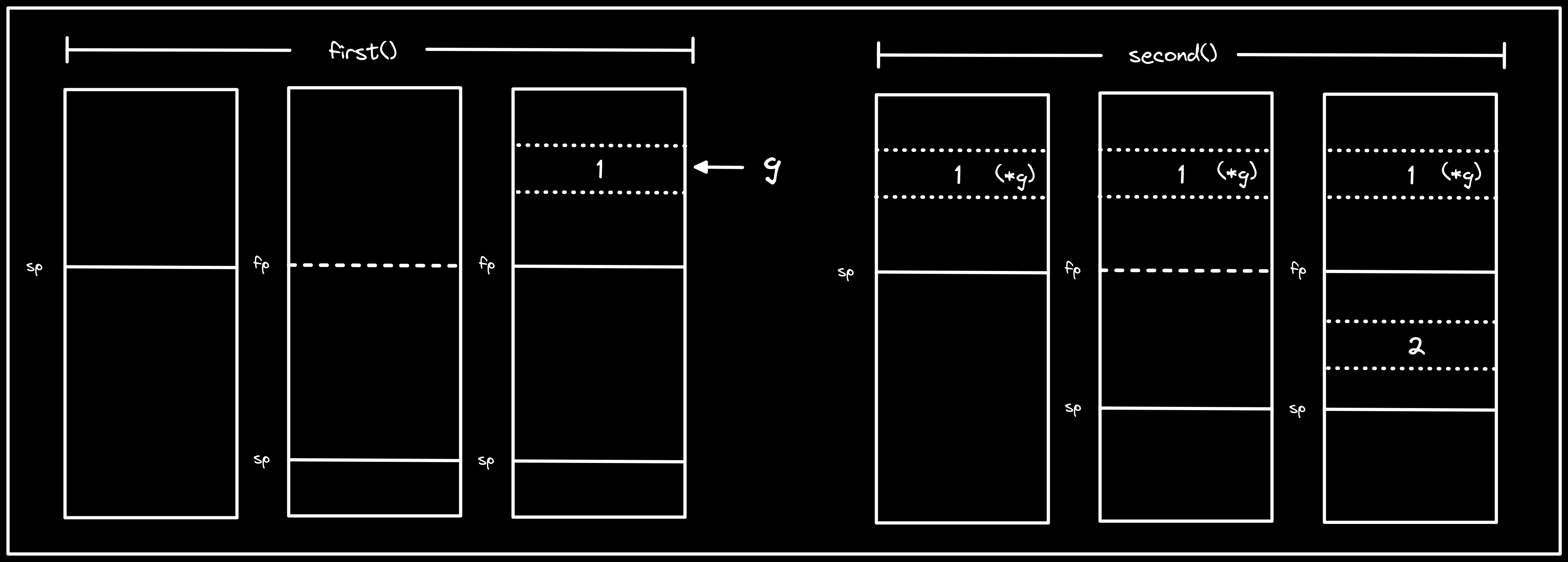
Description: visualization of
first()andsecond(), showing that the address ingis safely on the heap where it will not be impacted by the write of2to the stack insecond().
How does Rust handle this? Link to heading
Go, and other garbage collected languages, provide immense value to the programmer by protecting them from making potentially catastrophic memory management mistakes, but that protection comes at a cost. Generally speaking, writing to the heap is going to be more expensive that writing to the stack, and we also must accommodate for the scenarios where we are trying to write but the garbage collector is running.
In reality, there are additional penalties that one must pay for garbage collection that we have not explored here, but we’ll save those for another day.
Rust takes a different approach, providing similar (or stronger, as we’ll see in a moment) guarantees, but imposing a greater burden on the programmer, rather than the language runtime. Fortunately, the rust compiler provides very helpful error messages to help us understand why the operation we are trying to perform may lead to undesirable behavior. This is exemplified if we try to reproduce a program that looks similar to our C and Go implementations.
main.rs
static mut G: &i32 = &0;
fn first() {
let a = 1;
G = &a;
}
fn second() {
let _b: i64 = 2;
}
fn main() {
first();
second();
println!("{}", *G)
}
Attempting to compile this program results in three errors:
$ cargo build
Compiling blog-code v0.1.0 (/home/dan/code/github.com/hasheddan/blog-code)
error[E0597]: `a` does not live long enough
--> main.rs:5:9
|
5 | G = &a;
| ----^^
| | |
| | borrowed value does not live long enough
| assignment requires that `a` is borrowed for `'static`
6 | }
| - `a` dropped here while still borrowed
error[E0133]: use of mutable static is unsafe and requires unsafe function or block
--> main.rs:5:5
|
5 | G = &a;
| ^^^^^^ use of mutable static
|
= note: mutable statics can be mutated by multiple threads: aliasing violations or data races will cause undefined behavior
error[E0133]: use of mutable static is unsafe and requires unsafe function or block
--> main.rs:15:20
|
15 | println!("{}", *G)
| ^^ use of mutable static
|
= note: mutable statics can be mutated by multiple threads: aliasing violations or data races will cause undefined behavior
Rust Version: 1.58.0
Note: for more information on how to cross-compile Rust programs for RISC-V, check out this earlier post in the RISC-V Bytes series.
The second two are more obvious than the first, and actually happen to be the
same error (error[E0133]) in two different locations. Fortunately, the
compiler tells us exactly what is wrong: “use of mutable static is unsafe and
requires unsafe function or block”. This is an important, and sometimes
overlooked, distinction of Rust compared to other “memory safe” languages such
as Go. While Go protected us from implicitly overwriting memory, it did not
protect us from mutating a global variable (variables with 'static lifetimes
outlive all other lifetimes), which, as the additional note in our Rust compiler
error states, can lead to complex and dangerous bugs in multi-threaded programs.
However, Rust doesn’t say that we just can’t use mutable static variables. In
fact, the
documentation
points out that mutable statics “are still very useful”, especially when
integrating with C libraries. What Rust does force us to do is denote that their
usage is unsafe, making it quite obvious that the block of code should be
handled with care. Let’s update our program as instructed and recompile.
main.rs
static mut G: &i32 = &0;
fn first() {
let a = 1;
unsafe {
G = &a;
}
}
fn second() {
let _b: i64 = 2;
}
fn main() {
first();
second();
unsafe {
println!("{}", *G)
}
}
$ cargo build
Compiling blog-code v0.1.0 (/home/dan/code/github.com/hasheddan/blog-code)
error[E0597]: `a` does not live long enough
--> main.rs:6:13
|
6 | G = &a;
| ----^^
| | |
| | borrowed value does not live long enough
| assignment requires that `a` is borrowed for `'static`
7 | }
8 | }
| - `a` dropped here while still borrowed
Despite wrapping our assignment in an unsafe block, our first error persists,
illustrating another subtle benefit of Rust: writing some unsafe code does
not make the entire program unsafe. If this error was eliminated by our unsafe
block, we would still be susceptible to our use after return bug. However, the
compiler continues enforcing the lifetime constraints of the language here,
meaning that if a is to be borrowed by something that lives for a 'static
lifetime, it must also have a 'static lifetime. Adding the suggested lifetime
annotation not only allows us to compile successfully, but also ensures that a
does not live on the stack, meaning that a future procedure cannot overwrite its
value in memory.
main.rs
static mut G: &i32 = &0;
fn first() {
let a: &'static i32 = &1;
unsafe {
G = &a;
}
}
fn second() {
let _b: i64 = 2;
}
fn main() {
first();
second();
unsafe {
println!("{}", *G)
}
}
$ cargo build
Finished dev [unoptimized + debuginfo] target(s) in 0.00s
Running our program will result in the expected output of 1:
$ ./target/riscv64gc-unknown-linux-gnu/debug/blog-code
1
For completeness, let’s dump the machine code and bring out GDB to see what is actually being executed.
000000000001234a <_ZN9blog_code5first17h704821ce71949405E>:
1234a: 1141 addi sp,sp,-16
1234c: 00078517 auipc a0,0x78
12350: ae850513 addi a0,a0,-1304 # 89e34 <buffer_free+0x32>
12354: e42a sd a0,8(sp)
12356: 000ab597 auipc a1,0xab
1235a: 78a58593 addi a1,a1,1930 # bdae0 <_ZN9blog_code1G17hdf4e2a24b3404040E>
1235e: e188 sd a0,0(a1)
12360: 0141 addi sp,sp,16
12362: 8082 ret
0000000000012364 <_ZN9blog_code6second17h0dfb1109f83f0614E>:
12364: 1141 addi sp,sp,-16
12366: 4509 li a0,2
12368: e42a sd a0,8(sp)
1236a: 0141 addi sp,sp,16
1236c: 8082 ret
What are those funky symbols for
first()andsecond()? They are the result of name mangling, which allows languages to avoid symbol name conflicts when supporting features such as generics. You can read more about thelegacyandv0name mangling schemes in Rust in the v0 RFC.
This looks much more similar to our original C program, and we once again see
our familiar function prologue and epilogue. However, we also see that first()
and second() differ in that first() loads the address containing 1
(0x89e34), which is known at compile time, into a0, stores it on the stack
(which could be omitted in an optimized build), then updates G (0xbdae0) to
point to it. G now contains an address that is not part of the stack (the
address of a is actually in .rodata), so even though second() sets up a
16 byte stack frame and writes 2 to 8(sp), it will not impact the value
that G points to. We can see this in action in our debugger.
Start QEMU:
$ qemu-riscv64 -g 1234 target/riscv64gc-unknown-linux-gnu/debug/blog-code
Start GDB:
$ riscv64-unknown-linux-gnu-gdb target/riscv64gc-unknown-linux-gnu/debug/blog-code -ex "target remote :1234" -ex "break first" -ex "break second"
(gdb) c
Continuing.
Breakpoint 1, blog_code::first () at main.rs:4
4 let a: &'static i32 = &1;
(gdb) x/8i $pc
=> 0x1234c <_ZN9blog_code5first17h704821ce71949405E+2>: auipc a0,0x78
0x12350 <_ZN9blog_code5first17h704821ce71949405E+6>: addi a0,a0,-1304
0x12354 <_ZN9blog_code5first17h704821ce71949405E+10>: sd a0,8(sp)
0x12356 <_ZN9blog_code5first17h704821ce71949405E+12>: auipc a1,0xab
0x1235a <_ZN9blog_code5first17h704821ce71949405E+16>: addi a1,a1,1930
0x1235e <_ZN9blog_code5first17h704821ce71949405E+20>: sd a0,0(a1)
0x12360 <_ZN9blog_code5first17h704821ce71949405E+22>: addi sp,sp,16
0x12362 <_ZN9blog_code5first17h704821ce71949405E+24>: ret
(gdb) si
0x0000000000012350 4 let a: &'static i32 = &1;
(gdb) si
0x0000000000012354 4 let a: &'static i32 = &1;
(gdb) i r a0
a0 0x89e34 564788
(gdb) x /d 0x89e34
0x89e34: 1
(gdb) si
6 G = &a;
(gdb) si
0x000000000001235a 6 G = &a;
(gdb) si
0x000000000001235e 6 G = &a;
(gdb) i r a1
a1 0xbdae0 776928
(gdb) si
8 }
(gdb) x /x 0xbdae0
0xbdae0 <_ZN9blog_code1G17hdf4e2a24b3404040E>: 0x00089e34
After stepping through the body of first() we see that G (0xbdae0)
contains 0x00089e34, which contains the value 1. If we also step through
second(), we can see that all it does is write 2 to the stack.
(gdb) c
Continuing.
Breakpoint 2, blog_code::second () at main.rs:11
11 let _b: i64 = 2;
(gdb) x/8i $pc
=> 0x12368 <_ZN9blog_code6second17h0dfb1109f83f0614E+4>: sd a0,8(sp)
0x1236a <_ZN9blog_code6second17h0dfb1109f83f0614E+6>: addi sp,sp,16
0x1236c <_ZN9blog_code6second17h0dfb1109f83f0614E+8>: ret
0x1236e <_ZN9blog_code4main17h71d262632147b946E>: addi sp,sp,-112
0x12370 <_ZN9blog_code4main17h71d262632147b946E+2>: sd ra,104(sp)
0x12372 <_ZN9blog_code4main17h71d262632147b946E+4>: auipc ra,0x0
0x12376 <_ZN9blog_code4main17h71d262632147b946E+8>: jalr -40(ra)
0x1237a <_ZN9blog_code4main17h71d262632147b946E+12>: j 0x1237c <_ZN9blog_code4main17h71d262632147b946E+14>
(gdb) si
12 }
(gdb) x /d $sp+8
0x40007ffbe8: 2
This is similar to what we saw in our example Go program, though instead of
writing 1 to the heap, the compiler has already placed it at a known address
in the binary, so all that first() needs to do is update G to point to it.
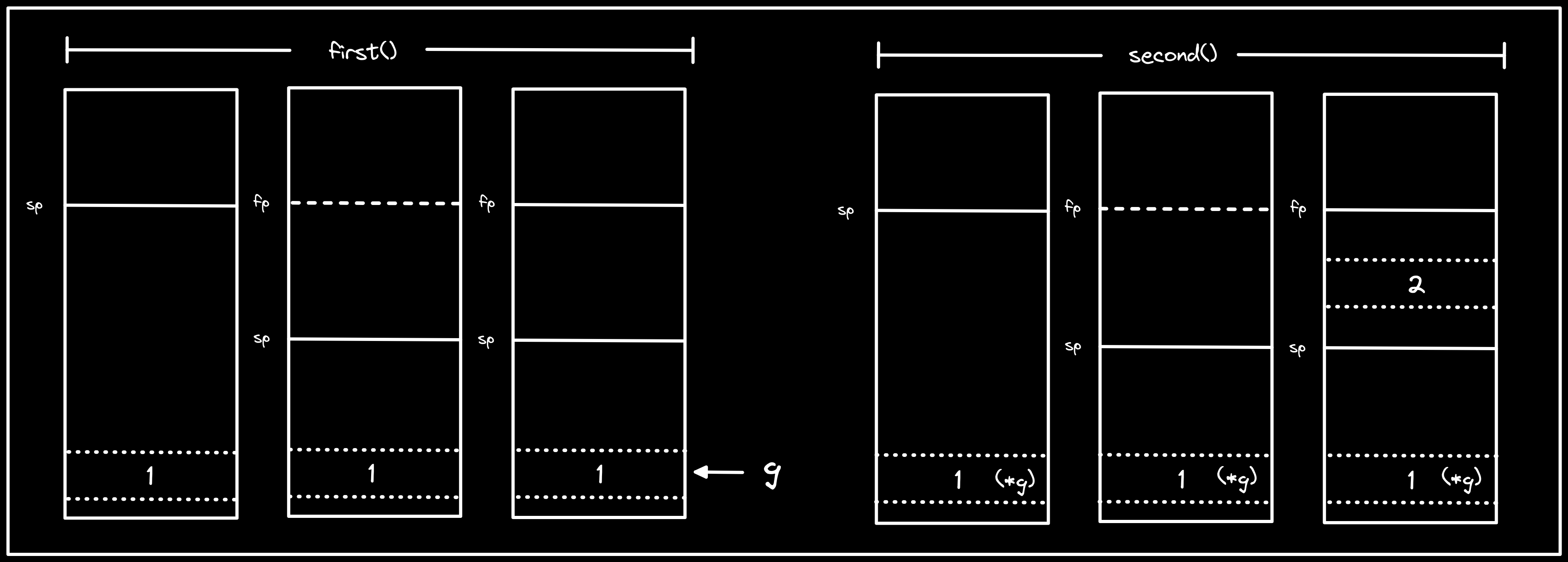
Description: visualization of
first()andsecond(), showing that1already exists in memory outside of the segment used for the stack.
While using a mutable static in this way is still likely not recommended in most scenarios, Rust provides some useful features to do so safely where possible, and explicitly where not.
Concluding Thoughts Link to heading
The example programs in this post (hopefully) do not resemble programs we write on a day-to-day basis, but they serve as useful illustrations of the approach each language takes to mitigate (or not) a certain class of bugs. Peeking behind the scenes at the compiler-generated machine code can bring to life some of the more abstract features of a language. In this post, diving into each binary exposed concepts related to garbage collection, escape analysis, lifetimes, mutability, and more.
As always, these posts are meant to serve as a useful resource for folks who are interested in learning more about RISC-V and low-level software in general. If I can do a better job of reaching that goal, or you have any questions or comments, please feel free to send me a message @hasheddan on Twitter!