As I work on moss and research modern
processor design patterns and techniques, I am also looking for patterns and
techniques from the past that, for one reason or another, have not persisted
into our modern machines. While on a run this week, I was listening to an old
Oxide and Friends
episode where Bryan,
Adam, and crew were reminiscing on the
SPARC instruction set architecture (ISA).
SPARC is a reduced instruction set computer (RISC) architecture originally
developed by Sun Microsystems,
with the first machine, the
SPARCstation1 (a.k.a. Sun 4/60,
a.k.a Campus), being delivered in 1987. It was heavily influenced by the early
RISC designs from David
Patterson
and team at Berkeley in the 1970s and 1980s, which is the same lineage from
which RISC-V has evolved. Given the
decision to base moss on
the RISC-V RV64I ISA, I was interested to learn more about the history and
finer details of SPARC.
The episode discusses a number of interesting attributes of the architecture, as well as some issues in specific implementations, but one in particular stuck out to me: register windows. As it turns out, register windows were not an innovation of SPARC, but rather a feature inherited from those early Berkeley RISC designs. In fact, the very first design, RISC I, describes register windows as a prominent component of making the simplified processor design feasible for legitimate computation.
“It would appear that such constraints would result in a machine with substantially poorer code density or poorer performance or both. In spite of these constraints, the resulting architecture competes favorably with other state-of-the-art machines such as VAX 11/780. This is largely because of an innovative new scheme of register organization we call overlapped register windows.”
- David A. Patterson and Carlo H. Sequin. 1998. RISC I: a reduced instruction set VLSI computer. (Page 217)
Conventions for Register Use Link to heading
I have previously written about how RISC-V uses
registers,
as well as what happens when we run out of
registers.
Additionally, we recently
explored the
Verilog implementation of the moss register file. As a brief recap, registers
are the fastest memory available to a processor, and thus the most desirable
location to store data. However, they are also typically the smallest memory,
with RISC-V supporting 32 general purpose registers (GPRs) in most
architectures; RV32E being the exception with 16 GPRs.
As detailed in the aforementioned posts, one important use of registers is passing data from one procedure to another. To do so, there needs to be an agreed upon convention for which registers the callee procedure (i.e. the one being called) may manipulate and not restore, and which must be restored prior to returning. Data in registers in the former category need to be persisted to a secondary location, such as L1-L3 cache or RAM, so that they can be recovered after control returns from the callee procedure. Registers in this group are referred to as caller-saved while those that must be restored are referred to as callee-saved Additionally, both the caller and callee procedures need to know what registers are used for passing arguments, and which are used for returning them. The table in this post outlines which of the 32 GPRs in RISC-V are preserved across calls and which are not.
A History of Register Windows Link to heading
One of the key insights in the development of the RISC architecture was the fact that the performance of a processor could be improved by supporting a small set of instructions that could be executed quickly and executing more of them. We have previously discussed the CPU performance equation, which includes the number of instructions required to define a program in the numerator (Instruction Count), meaning that, as one would expect, driving up the instruction count means worse performance. However, the RISC architecture is able to offset this increase with a larger decrease in cycles per instruction (CPI), which is also a factor in the numerator, thus driving the overall CPU time down.
Naturally, Patterson & Sequin were interested in identifying which operations in high-level languages (they evaluated C and Pascal) resulted in the largest number of RISC instructions required. If common operations in high-level languages reached a certain threshold in number of instructions required, the offset in decreased CPI may not have been enough to improve overall performance. Through their analysis, they identified the procedure call as the most expensive.
“Using procedures involves two groups of time-consuming operations: saving or restoring registers on each CALL or return, and passing parameters and results to and from the procedure. Because our measurements on high-level language programs indicate that local scalars are the most frequent operands, we wanted to support the allocation of locals in registers.”
- David A. Patterson and Carlo H. Sequin. 1998. RISC I: a reduced instruction set VLSI computer. (Page 218)
With this being the case, they asked the logical question: how could we eliminate some of this overhead? Interestingly, they were not the first to ask this question. Their paper sites two contemporaries when introducing register windows. The first is a lecture from Forest Baskett in 1978, which appears to have been lost to the sands of time. However, Baskett has had quite the illustrious career, founding the Western Research Laboratory at Digital Equipment Corporation (DEC) and serving as CTO at Silicon Graphics, Inc. (SGI), two companies that have been well chronicled in computing lore.
I feared the same fate for the second citation, but was able to find Richard L. Sites’ paper How to Use 1,000 Registers. Not to be outdone, Sites also had quite the career as a professor at UC San Diego and engineer at DEC, Adobe, and Google. In his paper, he makes an astute observation.
“As short-term register memories get larger, subroutine calls will get slower, unless we find better solutions to the stale data and alias problems.”
- Richard L. Sites. 1979. How to Use 1,000 Registers. (Page 529)
Put simply, if there are more registers accessible to and used by a given procedure, there is more work to do when saving and restoring them on a given procedure call. A solution is proposed in Section 5, Techniques for Effective Use of Large Short-Term Memories.
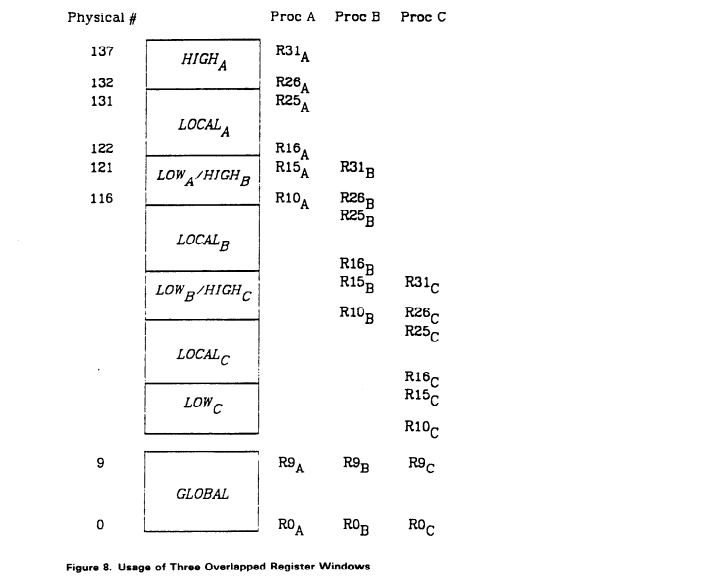
“Assuming that almost all registers are in use at the point of call, and almost all will be used by the subroutine (so that we cannot avoid come sort of save/restore), then one way to speed up the call linkage is to have duplicate register sets. Say there are four sets, 0-3, and that the calling subroutine is using set 1. Then the called routine just starts using set 2, and no data movement of set 1 to main memory is needed. This makes the subroutine call quite fast, and it also makes the linkage overhead no longer proportional to the number of resisters. When the subroutine returns, the machine just switches back from set 2 to set 1.”
- Richard L. Sites. 1979. How to Use 1,000 Registers. (Page 530)
There are some issues that need to be addressed with the proposed functionality, which Sites outlines in the paragraphs that follow. For example, what happens when the number of nested subroutines exceeds the number of register sets? Sites proposed a system that allowed for registers from parent procedures to be “dribbled back” into main memory on unused memory access cycles in the subroutines.
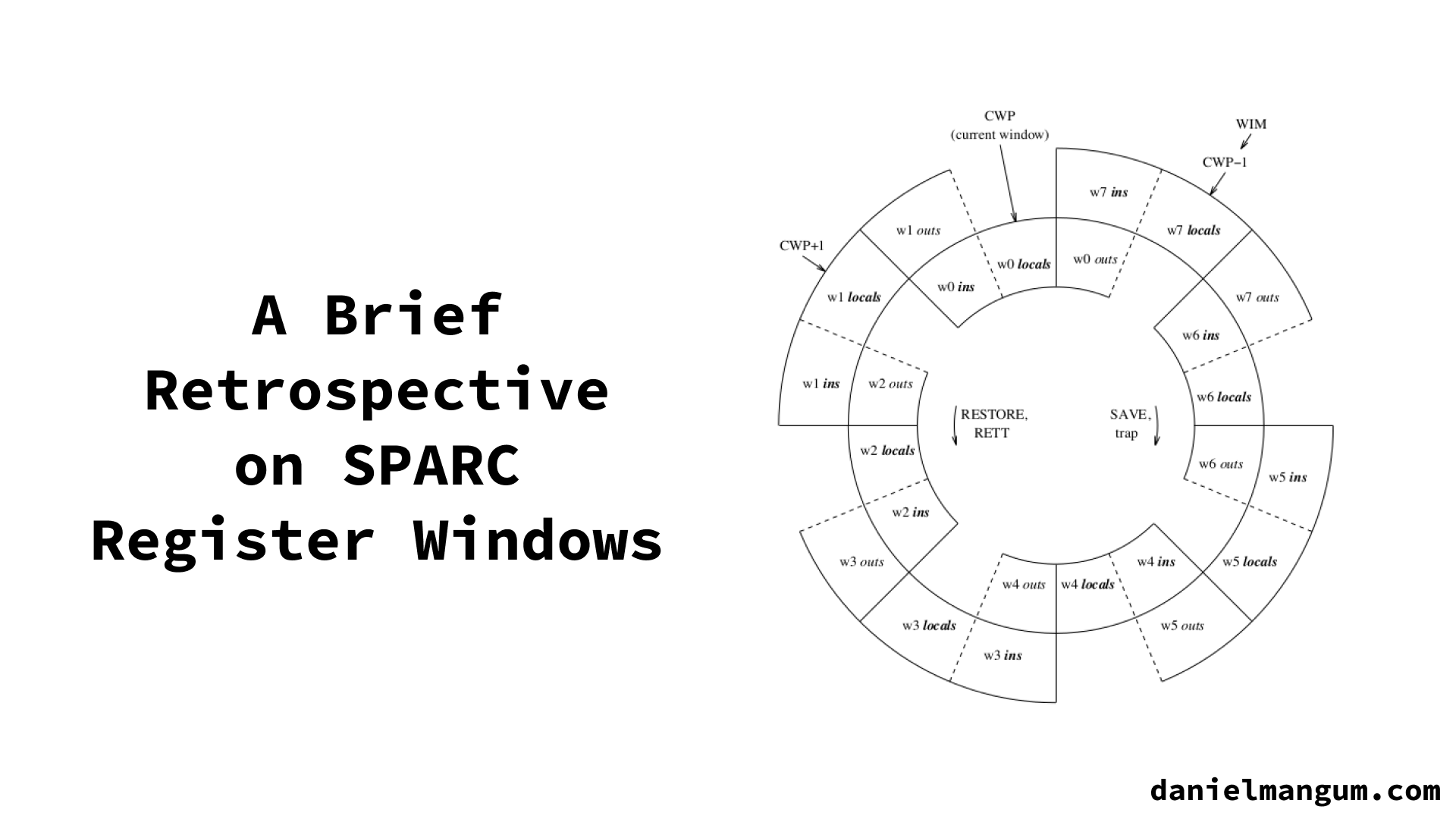
This cache of register sets, as Sites referred to them, were the precursor to Patterson & Sequin’s register windows, which build on this work while introducing a few variations. One such variation is born out of the previously described requirement for procedures to pass data between one another. Ideally, that data would be passed in the fastest memory: registers. However, if each procedure sees a different window, that is no longer feasible. To address the issue, Patterson & Sequin proposed that register windows overlap, meaning that the high registers of the caller become the low registers of the callee. This allows for the caller to pass parameters to the callee, and for the callee to pass return values back to the caller.
In addition to the overlapping windows, a set of 10 global registers was set aside and made accessible by all routines, as can bee seen in the diagram above. Another variation was that rather than “dribbling back” registers to main memory, Patterson & Sequin proposed underflow and overflow semantics that would cause traps to occur when the number of nested procedures exceeded the number of register windows. A software-defined trap handler could then be used to save and restore existing registers on a dedicated stack.
The last variation came in the form of how pointers were handled. Once again trying to avoid having to place data unnecessarily into main memory, Patterson & Sequin reserved a portion of the memory address space to registers, such that one procedure could access data in registers that were outside of its window.
SPARC Register Windows Link to heading
Register windows are mentioned as the first attribute of the SPARC ISA in the v8 architecture manual. In fact, the authors pay homage to the RISC I & II designs explicitly.
“SPARC, formulated at Sun Microsystems in 1985, is based on the RISC I & II designs engineered at the University of California at Berkeley from 1980 through 1982. the SPARC “register window” architecture, pioneered in UC Berkeley designs, allows for straightforward, high-performance compilers and a significant reduction in memory load/store instructions over other RISCs, particularly for large application programs.”
- The SPARC Architecture Manual, Version 8. 1990. (Page 4)
Even the diagram used in the registers section of the manual (Section 4) looks quite similar to the one from the RISC I design.
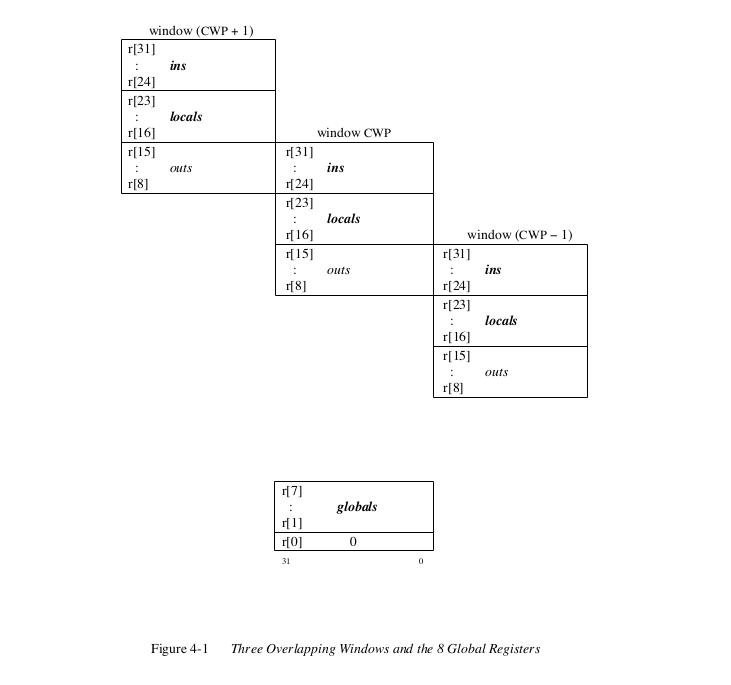
However, the good folks at Sun did put their own spin on register windows, opting to expose more knobs to programmers that allowed for fine-grained control over register window management.
“One difference between SPARC and the Berkeley RISC I & II is that SPARC provides greater flexibility to a compiler in its assignment of registers to program variables. SPARC is more flexible because register window management is not tied to procedure call and return (CALL and JMPL) instructions, as it is on the Berkeley machines. Instead, separate instructions (SAVE and RESTORE) provide register window management.”
- The SPARC Architecture Manual, Version 8. 1990. (Page 4)
This variation results in the ability to transfer control from one routine to another without changing the register window. This enables a number of windowing schemes, which are explored in greater detail in the appendix on software considerations (Appendix D, Page 203).
Exploring Register Windows Link to heading
To make the use of register windows more concrete, we can craft a minimal example. The following program does not perform any computation of value, but stepping through it illustrates how a given procedure sees its register window.
.section .text
main:
set 10, %o1
call sub1
nop
nop
sub1:
save %sp, -112, %sp
set 20, %o1
call sub2
nop
ret
restore
sub2:
set 30, %o1
retl
nop
Use the following commands to assemble and link the executable.
sparc-elf-as main.S
sparc-elf-ld a.out -o main
We can utilize the QEMU SPARC 32-bit userspace emulator to run the program on a
non-SPARC host. Specifying -g 1234 will cause QEMU to start its GDB server,
which will allow us to step through the program.
qemu-sparc-static -g 1234 test
With QEMU running, start GDB and connect it to the QEMU remote.
sparc-elf-gdb main -ex "target remote :1234"
Three registers will be of interest to us: the program counter (pc), output
register 1 (o1), and input register 1 (i1). We can make GDB print these on
every step with the following commands.
display /i $pc
display $o1
display $i1
We can view the state of all registers prior to starting with info registers.
(gdb) info registers
g0 0x0 0
g1 0x0 0
g2 0x0 0
g3 0x0 0
g4 0x0 0
g5 0x0 0
g6 0x0 0
g7 0x0 0
o0 0x0 0
o1 0x0 0
o2 0x0 0
o3 0x0 0
o4 0x0 0
o5 0x0 0
sp 0x407fff30 0x407fff30
o7 0x0 0
l0 0x0 0
l1 0x0 0
l2 0x0 0
l3 0x0 0
l4 0x0 0
l5 0x0 0
l6 0x0 0
l7 0x0 0
i0 0x0 0
i1 0x0 0
i2 0x0 0
i3 0x0 0
i4 0x0 0
i5 0x0 0
fp 0x0 0x0
i7 0x0 0
y 0x0 0
psr 0x4000000 [ ]
wim 0x1 1
tbr 0x0 0
pc 0x10054 0x10054 <main>
npc 0x10058 0x10058 <main+4>
fsr 0x0 [ ]
csr 0x0 0
Let’s step through the first few instructions.
1: x/i $pc
=> 0x10054 <main>: mov 0xa, %o1
2: $o1 = 0
3: $i1 = 0
(gdb) si
0x00010058 in main ()
1: x/i $pc
=> 0x10058 <main+4>: call 0x10064 <sub1>
0x1005c <main+8>: nop
2: $o1 = 10
3: $i1 = 0
(gdb) si
0x0001005c in main ()
1: x/i $pc
=> 0x1005c <main+8>: nop
2: $o1 = 10
3: $i1 = 0
(gdb) si
0x00010064 in sub1 ()
1: x/i $pc
=> 0x10064 <sub1>: save %sp, -112, %sp
2: $o1 = 10
3: $i1 = 0
You may notice that the
nopinstruction inmainexecutes after the call tosub1. This is due to the fact that SPARC uses delayed control transfer. We won’t dive into the rationale in this post, but it is also an architectural pattern that isn’t present, or perhaps isn’t as obviously present, in modern machines. We’ll explore more when I am working on pipelining inmoss.
All we have done thus far is load the value of 10 into the first output
register (o1), then jump to the first subroutine (sub1). Notably, jumping to
sub1 did not change the value of o1 as it is still seeing the same register
window. However, executing save illustrates a shift to the next window.
(gdb) si
0x00010068 in sub1 ()
1: x/i $pc
=> 0x10068 <sub1+4>: mov 0x14, %o1
2: $o1 = 0
3: $i1 = 10
As detailed in the SPARC architecture manual, the set of output registers of the
caller procedure (main) has become the set of input registers for the callee
(sub1) — o1 of main is i1 of sub1. The subsequent call to sub2
illustrates that shifting register windows is not required, as it operates on
the same o1 seen by sub1. We also use the retl (“return from leaf
procedure”) in sub2, which updates the pc to the address o7+8, rather than
ret (“return from procedure”), which updates the pc to the address i7+8,
because we did not shift register windows. If we had shifted register windows,
as we’ll see shortly when returning from sub1, we would use ret because the
return address placed in the output register (o7) of the previous procedure
would now reside in the input register (i7) of the current procedure.
Note that we offset the return address by
8in order to account for the delay slot instruction that follows thecalllocation but was executed prior to transfer of control.
(gdb) si
0x0001006c in sub1 ()
1: x/i $pc
=> 0x1006c <sub1+8>: call 0x1007c <sub2>
0x10070 <sub1+12>: nop
2: $o1 = 20
3: $i1 = 10
(gdb) si
0x00010070 in sub1 ()
1: x/i $pc
=> 0x10070 <sub1+12>: nop
2: $o1 = 20
3: $i1 = 10
(gdb) si
0x0001007c in sub2 ()
1: x/i $pc
=> 0x1007c <sub2>: mov 0x1e, %o1
2: $o1 = 20
3: $i1 = 10
(gdb) si
0x00010080 in sub2 ()
1: x/i $pc
=> 0x10080 <sub2+4>: retl
0x10084 <sub2+8>: nop
2: $o1 = 30
3: $i1 = 10
(gdb) si
0x00010084 in sub2 ()
1: x/i $pc
=> 0x10084 <sub2+8>: nop
2: $o1 = 30
3: $i1 = 10
(gdb) si
0x00010074 in sub1 ()
1: x/i $pc
=> 0x10074 <sub1+16>: ret
0x10078 <sub1+20>: restore
2: $o1 = 30
3: $i1 = 10
However, when we return back to sub1, we need to restore the previous register
window before transferring control back to main. This is accomplished with the
restore instruction.
(gdb) si
0x00010078 in sub1 ()
1: x/i $pc
=> 0x10078 <sub1+20>: restore
2: $o1 = 30
3: $i1 = 10
(gdb) si
0x00010060 in main ()
1: x/i $pc
=> 0x10060 <main+12>: nop
2: $o1 = 10
3: $i1 = 0
The value in o1 that we initially set in main (10) has been restored. This
program certainly does not show the full complexity of register windows, but it
should provide you with a starting point to dig deeper.
Why We Don’t Use Register Windows Link to heading
Register windows are curiously absent from most ISAs that are widely used today (i.e. x86, Arm, etc.). I discovered a number sources in which critiques of register windows are provided. A few examples are referenced below.
“It is just too hard to deal with the interrupts, and the spilling, and predicting performance.”
- Tom Lyon on the aforementioned Oxide and Friends episode.
“The register windows overlap partially, thus the out registers become renamed by SAVE to become the in registers of the called procedure. Thus, the memory traffic is reduced when going up and down the procedure call. Since this is a frequent operation, performance is improved. (That was the idea, anyway. The drawback is that upon interactions with the system the registers need to be flushed to the stack, necessitating a long sequence of writes to memory of data that is often mostly garbage. Register windows was a bad idea that was caused by simulation studies that considered only programs in isolation, as opposed to multitasking workloads, and by considering compilers with poor optimization. It also caused considerable problems in implementing high-end Sparc processors such as the SuperSparc, although more recent implementations have dealt effectively with the obstacles. Register windows is now part of the compatibility legacy and not easily removed from the architecture.)”
- Garo Bournoutian, University of California, San Diego. Understanding stacks and registers in the Sparc architecture(s).
“Although this idea seems great at first, there are a few disadvantages to windowing. First is that in large programs, where there is much recursion, the limited amount of physical registers fill up and you are back to the traditional push/pop stack usage, along with additional overhead of managing the windows and handling window overflow exceptions. Since it is hard to predict when the registers will overflow, performance analysis can be difficult. Also, hardware engineering becomes more difficult to implement the large amount of physical registers and multiplexers.”
- Saunders Roesser, James Madison University. Interesting Points of the SPARC Processor.
To summarize some of the consistent themes from these sources, there seems to be three primary issues with the design of register windows.
- Implementing register windows increases the complexity of the processor design. This attribute on its own is not reason to throw out the functionality, and could also be said for implementing any additional logic in a processor. However, it serves to illustrate that all processor functionality comes at a cost and must be justified by tangible performance improvements. For example, in the previously mentioned description of alternative register windowing schemes in the SPARC architecture manual, one pattern mentioned was not using register windows at all. If design complexity was free then perhaps an argument could be made that supporting register windows makes sense because a user can always opt not to utilize them. The issue with that outlook is that the complexity is not free, and mixed programming models can lead to incompatibility and poor user experience.
- There is not enough attention paid to the cost of register windows when interacting with the operating system. When just moving between procedures in a single program, as our minimal example demonstrated, a reasonable case can be made for the improvements offered by the increased number of registers offered by windowing. However, when transferring control from a program to the system, we now have many more registers that must be written to memory so that they can later be restored. The more often we switch between programs, the more costly this becomes.
- Reasoning about the performance of a program becomes more difficult. Because the number of registers is still limited, a program may overflow or underflow the current register window, resulting in a trap to the operating system. This not only requires the system to implement functionality to properly handle these cases, but also imposes an unpredictable performance penalty on the program.
Time has proven that register windows, while an interesting idea, do not provide the right set of performance and complexity tradeoffs. However, there is a key takeaway that can be gleaned from both the justification and critique of the functionality: when designing processors, it is vital to consider the holistic system. Programs do not exist in a vacuum, and changing one aspect of the computation model frequently results in unintended consequences in other areas. That being said, I am hopeful that the growing accessibility of processor design results in even more experimentation that we can learn from and improve upon. I am deeply grateful that we have the opportunity to look back on the tremendous work from folks at Berkeley, Sun, and elsewhere, and let it inform how we chart a path forward.