Sometimes I hear folks in the Crossplane community ask if they can just use Helm instead of opting into our package manager. The technical answer to this question is “yes”, but it typically represents a misinterpretation of what Crossplane is providing in a Kubernetes cluster. That being said, I completely understand why someone would ask this question, and quite frankly, I think the confusion is our fault. In Crossplane and across the Kubernetes community we lean in heavily to the idea that everything is “just an object”. While this is true in some respects, it has led us to providing a weak separation between operations that are defining the cluster and those that are consuming the cluster. Unsurprisingly, this is not the first time in the history of computing that a system has skewed towards flexibility. In fact, the basic task of programming a computer has slowly migrated from extremely flexible assembly instructions, to languages with high levels of abstraction and constraints. While low-level access to a machine is still necessary in some cases, the vast majority of code that is written today is better off interfacing with the hardware through a level of abstraction that offers protection, whether via a runtime or the compiler. These abstractions are presented in the form of a type system.
What is a Type System? Link to heading
I don’t know how to tell you this, but types aren’t real. Well, maybe a less controversial way to say that is that types are artificial. That is, they are a self-imposed limitation that we are layering on the fundamental constraints of a system. The complexities of deciding what limitations we place and how strict they are is the reason that we continue to build new programming languages despite the constraints of the underlying hardware changing at a much slower pace.
The typical programming language offers a set of built-in types. These may
be primitive types, which represent simple numeric and logical values, such as
an integer or boolean, or composite types, which express logic at a higher
level, such as an array. Many languages also support user-defined types,
which offer a way to define your own types using the built-in types. For
example, Go allows you to create your own primitive types
that add custom functionality, such as attaching methods to an int, as well as
your own composite types by defining members and methods on a struct.
type CoolInteger int
func (c CoolInteger) Print(w io.Writer) {
fmt.Fprintf(w, "Cool Integer: %d", c)
}
type CoolType struct {
some int
built string
in bool
types []float32
}
When you define your own types, you are building on the constraints of the
built-in types to be able to safely express higher-level concepts. Almost all
“modern” programming languages also support abstract types. An abstract type
is one that is defined by its behavior rather than its implementation. Once
again, a built-in type, such as an interface, allows us to define these for
ourselves.
type CoolAbstractType interface {
This()
Is() error
My() int
Behavior() string
}
There are many other classifications of types, such as algebraic data types, references, functions, and more, but today we are going to focus in on primitive, composite, and abstract types. When we write a program with any complexity, we typically are doing a mix of defining types and using them. Depending on the language, these may be closely related or entirely disjoint activities.
Somewhere a programming language theory graduate student is screaming at me.
A Note on Safety Link to heading
In the preceding section I used the term “safely” to describe how we implement
higher-level logic. The degree of safety we get from a language is highly
dependant on the type system. Safety guarantees are propagated from built-in
types to the user-defined types constructed on top of them. For instance, a
language like Rust (ignoring unsafe code for a
moment) does not allow for simultaneous mutable ownership of the same data,
while a language like C gives the programmer unfettered access to the machine’s
resources. The machine is offering the same capabilities to both of these
languages, but Rust is giving us a layer of abstraction that prevents us from
using the machine in some “unsafe” ways. However, importantly, the concept of
safety that Rust gives us has to be implemented by Rust itself, and the code
that turns an “unsafe system” (the machine) into a “safe system” (the Rust
compiler) is inherently doing some unsafe things.
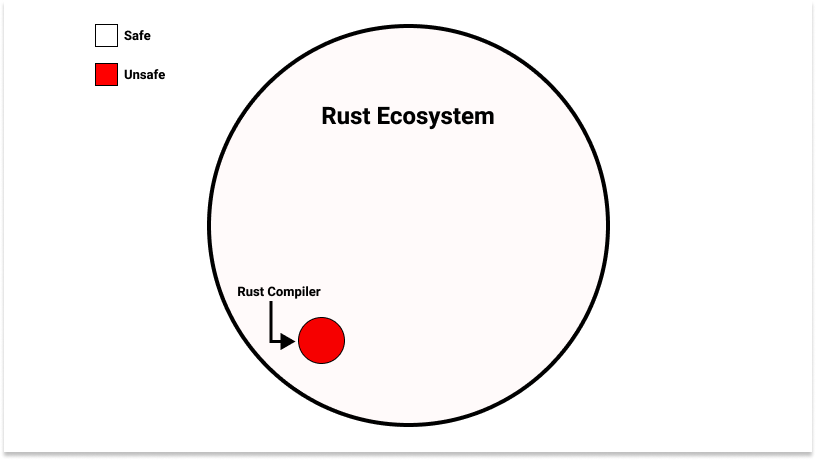
This would seem problematic: the system that is enforcing our safety guarantees is itself not safe. On the other hand, something must implement the safety, so what Rust programmers are collectively saying is: “let’s shrink the amount of unsafe operations we need to do down to the bare necessities, standardize them in a single system, and test that system rigorously”. If we have confidence in the correctness of that small system, arbitrarily large systems can be built on top of it. This is the same premise behind hardware privilege levels and the operating systems that utilize them.
The Kubernetes Type System Link to heading
Kubernetes allows you to add new types (kind in Kubernetes parlance) by
creating a CustomResourceDefinition
(CRD).
When we add a new CRD to a Kubernetes cluster, we may, at first glance, view the
operation as analogous to adding a new user-defined type. We are using a
built-in primitive to define something that we can then create instances of.
From this perspective, it makes sense why we might use the same tool, whether it
be Helm, Kustomize, or plain old kubectl apply, to
manage our type definitions and instances. If we are drawing a comparison to
programs we write, we are defining our struct and creating instances of it in
the same place.
However, when we define a new type in Kubernetes, we typically also want to add some associated behavior. This takes the form of a controller, which essentially performs some computation in response to the creation, update, or deletion of instances of the type defined by our CRD. Kubernetes itself places no limits on this computation, and while there are many frameworks for writing idiomatic controllers, there is no check to say “you probably don’t want to do that”. If Kubernetes is the machine we are programming, writing controllers is like writing C.
If you are only using Kubernetes to run ephemeral containerized workloads and your controllers are performing non-critical tasks, this might not be too scary for you. Odds are this is not the case though, as Kubernetes has grown far beyond a container orchestration platform, even to the point that projects like kcp (among others) are working to make it easy to use Kubernetes without many of the built-in APIs. And this gets to crux of the issue: we view adding CRDs and controllers to a cluster as adding user-defined types, when in reality it is much more akin to adding built-in types. Another way to say it is that adding CRDs and controllers is like expanding that small bit of unsafe code in the Rust ecosystem. We don’t expect every developer to write their own compiler, why are we expecting every DevOps engineer (whatever the flavor of the month definition of that role is) to write controllers? It’s not that folks aren’t capable, it’s that it is not an efficient use of time and resources.
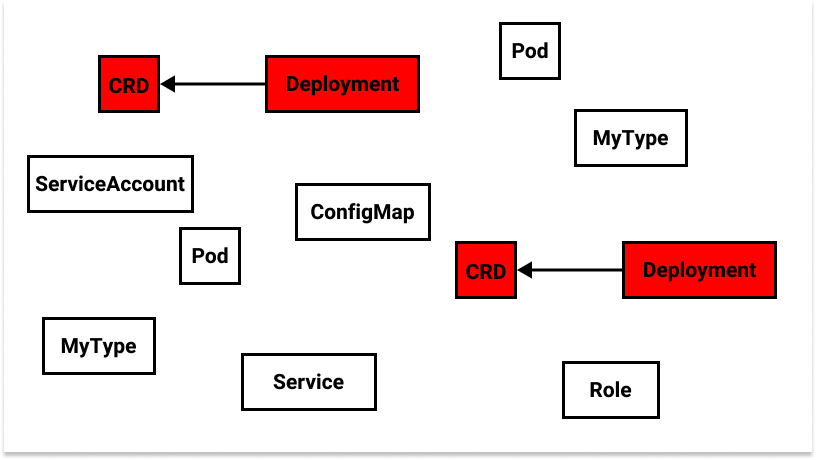
This “big bag of objects” in a cluster includes many instances of Kubernetes native built-in types (e.g.
Pod,Service), a few custom built-in types (e.g.CustomResourceDefinition+Deployment), and a few instances of those custom built-in types (e.g.MyType), but we have no concept of user-defined types.
So is the answer for an organization to only use vendor-backed or reputable open source controllers to extend Kubernetes? I don’t think that is a realistic scenario. Organizations are complex and if they want to go “all in” on the Kubernetes API, which is quickly becoming a POSIX-like interface (i.e. ubiquitous), they are going to eventually find themselves needing to add some custom functionality. What may be surprising to some organizations is that, even if you are small, that day will likely come sooner than you expect. So we’ve found ourselves at an impasse: we need custom functionality, but the overhead (dare I say “danger”) of writing and maintaining our controllers is too great.
Do Namespaces Address This? Link to heading
Namespaces
are primarily used in Kubernetes for categorization and isolation via
role-based access control
(RBAC). Many
types are namespace-scoped (e.g. Pod, Service, Deployment), meaning that
their instances must be associated with a single namespace, while others are
cluster-scoped (e.g. CustomResourceDefinition, ClusterRole,
PersistentVolume). Namespaces are not critical to the concepts we are talking
about today, but the “big bag of objects” diagram in the preceding section is
bound to make someone upset, and it is worth distinguishing what namespaces give
us vs. what a type system gives us. Fortunately, most programming languages are
namespaced as
well, and
this gives us a nice parallel. Namespaces are a wonderful way of grouping types
and preventing library consumers from accessing things they shouldn’t (e.g. by
using private identifiers), but they are a way to organize a program, not build
a compiler. In other words, they are for providing protections around
user-defined types.
Namespaces are a useful tool, but only if the type system they are built on is already sound. Unfortunately, as we covered in the previous section, our CRDs and controllers are expanding our type system, not building on top of it, so namespaces aren’t going to help us much.
An important attribute of CRDs is that they allow you to define cluster-scoped or namespace-scoped types (or both if you are using Crossplane). Namespaces are an important part of the type system we want to build, they just aren’t building it for us.
A Model for User-Defined Types Link to heading
If you ask anyone who is moderately familiar with Crossplane what its value proposition is they won’t miss a beat: provisioning cloud infrastructure using the Kubernetes API. We even say so on the front page. However, if you dig a bit deeper, you’ll find that all of the components of the core system actually have nothing to do with cloud infrastructure specifically. The Crossplane community often talks about building “control planes”, which can be thought of as Kubernetes clusters plus additional APIs. Your control plane is your distributed systems programming language, Crossplane is your compiler.
How does this work? Since I started this post talking about Crossplane packages, let’s begin there. Crossplane offers two types of packages: Providers and Configurations. These map quite nicely to our built-in types and user-defined types. Providers are just CRDs and their controllers packaged up into an OCI image. They look like other Kubernetes add-ons you see in the wild, with the difference being that they are installed via the Crossplane package manager, which provides additional guarantees, such as preventing multiple Providers from acting on the same types.
Exclusive ownership of mutable data? That sounds like something we talked about earlier!
Providers supply the built-in types of your distributed systems programming language. Like the Rust compiler, subject matter experts who dedicate their time and energy to making behavior correct build these (more on this in a bit), which allows everyone else to build on top of them safely.
Configurations supply user-defined types. This works through a Crossplane
feature called
composition, which
is controlled by the CompositeResourceDefinition (XRD) (though very closely
related, this is not the same thing as a CRD) and Composition types. XRDs are
how we define abstract types, while Compositions are how we define
composite types. Just like the parallel concepts in programming languages,
there can be many Compositions that satisfy the interface defined by a given
XRD, bringing
polymorphism to
your control plane APIs. A single Composition is selected at “run time” (i.e.
when a user creates an instance of the type defined by an XRD) based on
attributes of the environment, essentially employing the same techniques as
dynamic dispatch. A
Composition embeds one or more resources that Crossplane’s composition engine
renders based on the specification of the Composition and the values passed in
the instance of the type defined by the XRD. The embedded resources may be
instances of types provided by installed Provider packages (i.e. built-in
types) or may be types defined by other XRDs (i.e. other user-defined types).
This allows for powerful stacking of user-defined types to create higher-level
abstractions.
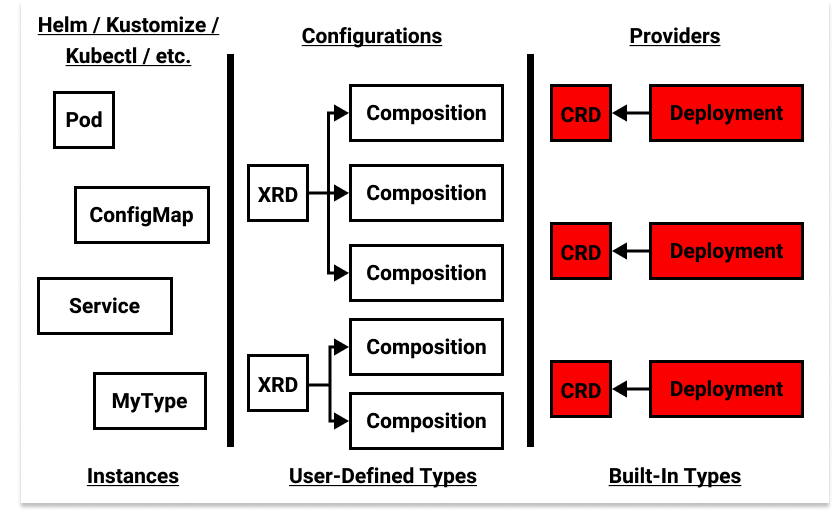
Not pictured: Kubernetes native built-in type implementations (i.e. the API server), which exist at the same level as Providers.
A programming language’s type system gives you a way to safely define your program. In Kubernetes, your program is an application packaged up into something like a Helm chart or a Carvel package. Crossplane gives you a way to build the type system that governs it.
If you want to learn more about how all of these mechanisms work under the hood, I wrote about packages here and composition here.
Flexibility in the Compiler Link to heading
One of the first things we said about programming languages in this post is that
we keep making new ones. A key attribute of successful languages is a fierce
dedication to a set of values, while still providing escape hatches for
exceptional use-cases (e.g. unsafe blocks in Rust). Sometimes I am a little
brash, but I’m not brash enough to sit here and say that Crossplane has
implemented the one true mechanism for defining types in Kubernetes. Though I
called Crossplane a compiler, it’s more like a compiler framework (see Is
Crossplane the Infrastructure
LLVM?).
A more apt term than “compiler framework” for describing what Crossplane does could be “type system manager”.
We know at this point that CRDs and controllers (i.e. Providers) are terrifyingly flexible, so we are mostly unconstrained with our built-in types. Fortunately, composition (i.e. the engine that turns instances of user-defined types into a set of built-in types) will also soon be pluggable. This means that the way you define relationships between your abstract types and your composite types can be expanded to cover additional use-cases. The point is that Crossplane is giving you the tools to build a type system, with some solid defaults, but it isn’t forcing one on you. What we would like to do is force using some type system.
Who Writes the Controllers? Link to heading
To re-emphasize my earlier point, writing controllers is not about some skill level that one group has and another does not. Rather, it is simply about who has the time and resources to invest in writing them well, creating that smaller bit of trusted unsafe code that allows us to safely build arbitrarily large abstractions on top. Today this looks like subject matter experts in various fields. For instance, the folks working on cert-manager know a lot about managing TLS certificates and the folks working on Knative know a lot about serverless compute. In the Crossplane community, we do a lot of work on writing CRDs and controllers (Providers) for cloud providers, and well, really any APIs folks want to access via Kubernetes. Along the way we put effort into standardizing common access patterns and functionality so that other folks with the time and energy can come along and build missing Providers.
However, ultimately the folks who know the API being targeted the best should be owning the development of its Provider. They have the most context and expertise, and they can ensure that trusted code that supplies built-in types for customers’ control planes offers the level of safety they need to build their user-defined types on top. The Crossplane community does a great job of writing Providers (in my extremely biased opinion), but if I am AWS, GCP, Microsoft, etc. I want to be owning my Provider. Not only that, I want to be building reference architectures in Configuration packages that help my customers compose their platforms safely. Expressive type systems allow for implementations to easily be switched out at each layer of abstraction. When users have this power, I want my implementation to be the best.
Final Thoughts Link to heading
I hope the takeaway from this post is not that Crossplane solves all of your problems, but rather an acknowledgement that the language we use for programming our distributed systems is lacking key features – features that we have collectively deemed useful in the context of writing software. We know that these features can be implemented in many different ways, and walking the line between adhering to a set of values and offering needed flexibility is hard. If we are going to do this right, we need everyone’s voice in the room. Come join us.